Ver 14以降の機能です。Ver 15では、コマンドを追加しました。
Ver 13以前から、コマンド機能が変わりました。
インポートCSVと一括更新で利用できます。
コマンドとは
インポートCSVでは、CSVから読み込んだ文字列を、指定した条件や正規表現によって変更できます。
コマンドによって、その変更を行うことが出来ます。
例1
次の、CSVファイルがあるとします。

住宅種類で、1は自宅、2は会社を宛先としています。
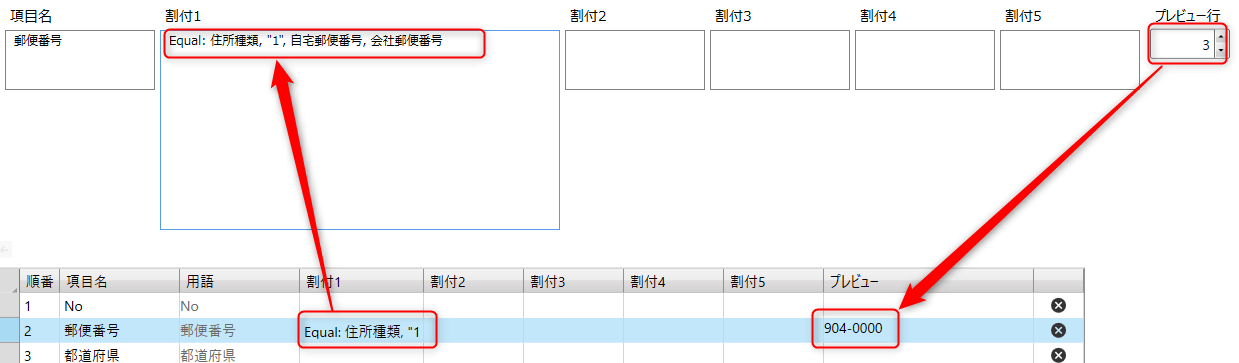
郵便番号の、割当を次のコマンドにします。
Equal: 住所種類, "1", 自宅郵便番号, 会社郵便番号
このコマンドで、住宅種類が"1"の時、自宅郵便番号にする。違う時は、会社郵便番号にする。になります。
画像の例では、プレビュー行が3なので、3行目の会社郵便番号「904-0000」が表示されています。
例2
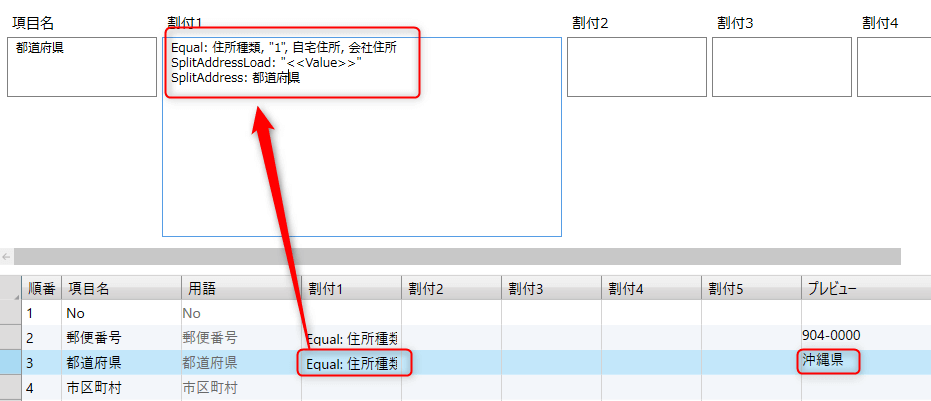
Equal: 住所種類, "1", 自宅住所, 会社住所
SplitAddressLoad: "<<Value>>"
SplitAddress: 都道府県
上から、1行ずつ評価されます。
- Equal: で、住所種類が、1の時はコンテントを自宅住所の値にします。違う時はコンテントを会社住所の値にします。
- SplitAddressLoad: "<<Value>>" で、分割対象の住所を、"<<Value>>"(直前のコンテント)を読み込みます。従って、自宅住所か会社住所になります。
- SplitAddress: 都道府県 で、SplitAddressLoadで読み込まれた住所から、都道府県を、コンテントとして表示します。
住所を分割した後は、例えば、次のようにSplitAddressを配置します。

- 市区町村 SplitAddress:政令市郡_市区町村
- 住所1 SplitAddress:住所1
- 住所2 SplitAddress:住所2
割当
割当は、1~5まであります。
それぞれの割当に、改行で区切って、複数のコマンドを設定できます。
前置文字、コンテント、後置文字
の3つの値を、割当で指定できます。
コマンドで操作するのは、主に、真ん中のコンテント(内容)です。
一覧
- Load
- AddContent
- AddBeforeWord
- AddAfterWord
- Omit
- SplitAddressLoad
- SplitAddress
- Equal
- NotEqual
- IsTrue
- IsFalse
- RegexReplace
- RegexMatches
- RegexIsMatch
ToHiragana
ToKatakana
ToHankaku
ToZenkaku
ToHankakuKana
ToZenkakuKana
ToPadding
Trim
TrimEnd
TrimStart
Replace
パラメータ
コマンドには、パラメータ(引数)を指定します。
パラメータには、次の種類があります。
- ""で囲まれない文字 ヘッダー名や、列番号として認識されます。
- ""で囲まれた文字 文字列になります。
- "<<Value>>" そのコマンドの直前で算出されているコンテントです。
- optionのパラメータ 省略するか、0~5の数値です。
Load
Load: para1, para2, para3
para1 前置文字
para2 コンテント
para3 後置文字
を読み込みます
AddContent
AddContent: para1, para2, para3, para4, para5
para1からpara5を、コンテントに追加します。
para2~para5まで省略できます。
AddBeforeWord
AddBeforeWord: para1, para2, para3, para4, para5
para1からpara5を、前置文字に追加します。
para2~para5まで省略できます。
AddAfterWord
AddAfterWord: para1, para2, para3, para4, para5
para1からpara5を、後置文字に追加します。
para2~para5まで省略できます。
Omit
Omit: A, B
AとBとが一致するときは、その割当の前置文字・コンテント・後置文字を全て""にして終了します。
SplitAddressLoad
SplitAddressLoad: parameter
分割する住所を読み込みます。コンテントとして、算出されるわけではありません。
次の、SplitAddressコマンドで、この読み込んだ住所を元に、住所を分割します。
分割例
CSVの元データの住所が分割されていない時、住所を分割してインポートできます。
元データ:福井県あわら市○○1-1-1 ×××
を
- 福井県
- あわら市
- ○○1-1-1
- ×××
のように分割できます。
SplitAddress
SplitAddress: parameter
SplitAddress:都道府県
SplitAddress:政令市郡_市区町村 郡を含めた、政令市・郡 + 市区町村
SplitAddress:政令市_市区町村 郡を除いた、政令市 + 市区町村
SplitAddress:住所1_2 市区町村以降の住所。文字列の中の改行は、半角空白に置き換えます。
SplitAddress:住所1 市区町村以降の住所で、最初の空白・改行で区切った、最初の部分
SplitAddress:住所2 市区町村以降の住所で、最初の空白・改行で区切った、2番目以降の部分。文字列の中の改行は、半角空白に置き換えます。
SplitAddress:都道府県ふりがな
SplitAddress:政令市郡_市区町村ふりがな
SplitAddress:政令市_市区町村ふりがな
SplitAddress:都道府県フリガナ
SplitAddress:政令市郡_市区町村フリガナ
SplitAddress:政令市_市区町村フリガナ
Equal
Equal: A, B, value1, value2, option
AとBとが一致する時は、value1を返す。
一致しない時は、value2を返す。
option AとBとが一致する時は、true, 一致しない時は、falseとする。
| option | true | false |
| 省略か0 | value1 | value2 |
| 1 | value1を追加 | value2を追加 |
| 2 | value1にして、終了 | value2 |
| 3 | value1 | value2にして、終了 |
| 4 | value1を追加して、終了 | value2を追加 |
| 5 | value1を追加 | value2を追加して、終了 |
終了とは、このコマンドの後に別のコマンドがあっても、このコマンドで終了します。
NotEqual
NotEqual: A, B, value1, value2, option
AとBとが一致しない時は、value1を返す。
一致する時は、value2を返す。
option AとBとが一致しない時は、true, 一致する時は、falseとする。
| option | true | false |
| 省略か0 | value1 | value2 |
| 1 | value1を追加 | value2を追加 |
| 2 | value1にして、終了 | value2 |
| 3 | value1 | value2にして、終了 |
| 4 | value1を追加して、終了 | value2を追加 |
| 5 | value1を追加 | value2を追加して、終了 |
終了とは、このコマンドの後に別のコマンドがあっても、このコマンドで終了します。
IsTrue
IsTrue: A, value1, value2, option
Aが、true、はい、yes、1の時(大文字小文字どちらでも)は、value1を返す。
それ以外の時は、value2を返す。
option AがIsTrueの時は、true, それ以外の時は、falseとする。
| option | true | false |
| 省略か0 | value1 | value2 |
| 1 | value1を追加 | value2を追加 |
| 2 | value1にして、終了 | value2 |
| 3 | value1 | value2にして、終了 |
| 4 | value1を追加して、終了 | value2を追加 |
| 5 | value1を追加 | value2を追加して、終了 |
終了とは、このコマンドの後に別のコマンドがあっても、このコマンドで終了します。
IsFalse
IsFalse: A, value1, value2, option
Aが、true、はい、yes、1でなければ(大文字小文字どちらでも)は、value1を返す。
それ以外の時は、value2を返す。
option AがIsFalseの時は、true, それ以外の時は、falseとする。
| option | true | false |
| 省略か0 | value1 | value2 |
| 1 | value1を追加 | value2を追加 |
| 2 | value1にして、終了 | value2 |
| 3 | value1 | value2にして、終了 |
| 4 | value1を追加して、終了 | value2を追加 |
| 5 | value1を追加 | value2を追加して、終了 |
終了とは、このコマンドの後に別のコマンドがあっても、このコマンドで終了します。
RegexReplace
RegexReplace: input, pattern, replacement
inputに、pattern(正規表現パターン)で一致する部分を、replacement(置換文字列)で置き換えて返します。
例3
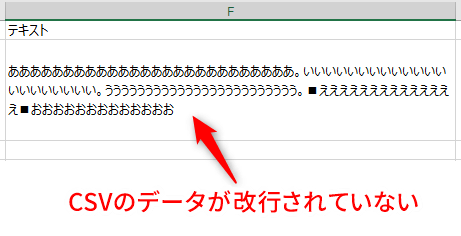
「。」の後で改行し、「■」の前で改行する方法です。
RegexReplace: テキスト, "。", "。\r\n"
RegexReplace: "<<Value>>", "■", "\r\n■"
1行目 テキストのヘッダー名の値がinputです。"。"に一致したら "。\r\n"に置き換えます。置き換えた値が、この時点でのコンテントです。
2行目 "<<Value>>"で直前のコンテント(1行目の結果)が、inputです。"■"に一致したら"\r\n■"に置き換えます。

RegexMatches
RegexMatches: input, pattern
inputに、pattern(正規表現パターン)で一致する値をすべて結合して返す。
例4
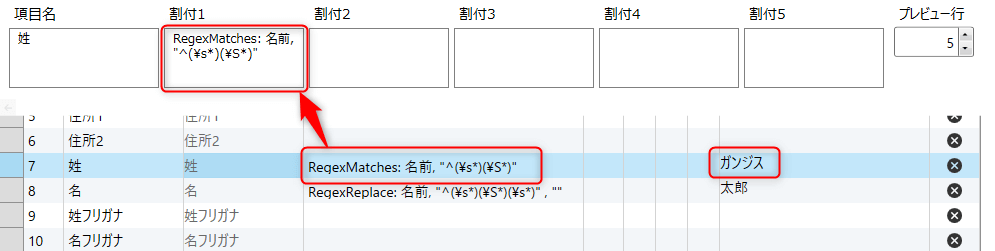
画像では、「ガンジス 太郎」という空白で区切られたCSVの文字列を、姓・名にして、分割しています。
姓のところは、
RegexMatches: 名前, "^(\s*)(\S*)"
行の先頭から開始して、空白があるなら一致、空白でない文字列に一致 という正規表現です。
名のところは、
RegexReplace: 名前, "^(\s*)(\S*)(\s*)" , ""
「行の先頭から開始して、空白があるなら一致、空白でない文字列に一致、空白があるなら一致」した部分を、""に置き換えます。その為、残りの部分が「名」として算出されます。
例5
RegexMatches:日付,"^\d\d\d\d"
日付の先頭から4桁の数字に一致。該当年に設定すると良いです。
RegexIsMatch
RegexIsMatch: input, pattern, value1, value2
inputに、pattern(正規表現パターン)で一致すれば、value1を返す。そうでない時は、value2を返す。
正規表現について
ひらがなとカタカナ、半角と全角の文字変換
- ToHiragana 全角カタカナを全角ひらがなに変換
- ToKatakana 全角ひらがなを全角カタカナに変換
- ToHankaku 全角英数字および記号を半角英数字および記号に変換
- ToZenkaku 半角英数字および記号を全角に変換
- ToHankakuKana 全角カタカナを半角カタカナに変換
- ToZenkakuKana 半角カタカナを全角カタカナに変換
- ToPadding 「は゛」を「ば」のように、濁点や半濁点を前の文字と合わせて1つの文字に変換
例:
ToHankakuKana: parameter
parameterを変換して、返します。
空白を削除する
- Trim 文字列の両端から空白を削除
- TrimEnd 文字列の末尾から空白を削除
- TrimStart 文字列の先頭から空白を削除
例:
Trim: parameter
parameterの両端から空白を削除して、返します。
Replace
Replace: input, oldValue, newValue
文字列を置換する。inputの文字列のうち、oldValueに一致した部分を、newValueに置換して返す。
例1
Replace: "株式会社ガンジス", "株式会社", ""
では、"株式会社"が空の文字""となって削除され、"ガンジス"の文字列が返されます。
例2
Replace: "<<Value>>", "(株)", "株式会社"
とすると、その行の直前で算出されているコンテントの文字列から、(株)を株式会社に置換して返します。
参照